Spring Cloud入门之Gateway篇
前言
在微服务架构中,一个系统通常会被划分为多个子模块,每个模块之间的调用该如何实现?如果每个子模块都记录调用的地址就会增加系统的复杂度,显然是很不利于后期的维护,如果每个服务之间的认证方式不同的话就需要适配不同的认证方式以及解决跨域的问题,所以我们就需要使用网关来解决这个问题。
简介
Spring Cloud Gateway是Spring Cloud 微服务生态下的网关组件。Spring Cloud Gateway 是基于 Spring 5 和 Spring Boot 2 搭建的,本质上是一个 Spring Boot 应用。Spring Cloud Gateway 使用了 Spring WebFlux 非阻塞网络框架,网络层默认使用了高性能非阻塞的 Netty Server。
Spring Cloud Gateway具有以下特点:
- 基于 Spring Framework 5、Project Reactor 和 Spring Boot 2.0 构建
- 能够匹配任何请求属性上的路由
- 断言和筛选器特定于路由
- 断路器集成
- Spring Cloud发现客户端集成
- 易于编写的断言和过滤器
- 请求速率限制
- 路径重写
工作原理:
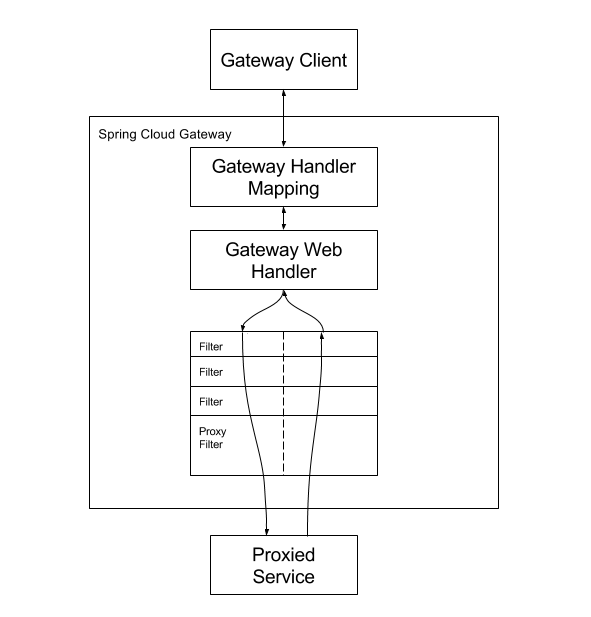
Route(路由): 一个 Route 由路由 ID,转发 URI,多个 Predicates 以及多个 Filters 构成。Gateway 上可以配置多个 Routes。处理请求时会按优先级排序,找到第一个满足所有 Predicates 的 Route
Predicate(断言): 表示路由的匹配条件,可以用来匹配请求的各种属性,如请求路径、方法、header 等。一个 Route 可以包含多个子 Predicates,多个子 Predicates 最终会合并成一个
Filter(过滤器): 过滤器包括了处理请求和响应的逻辑,可以分为 pre 和 post 两个阶段。多个 Filter 在 pre 阶段会按优先级高到低顺序执行,post 阶段则是反向执行。Gateway 包括两类 Filter
实现
先创建一个项目gateway-server,添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
修改yml配置,因为我们需要将网关注册到Eureka所以相关的依赖和配置也需要加上,后面会更新使用nacos来集成网关
server:
port: 80
spring:
application:
name: gateway-server
cloud:
gateway:
enabled: true #开启网关
routes:
- id: login-service-route #唯一标识。默认是一个UUID
uri: http://localhost:8081 #这个就是拦截的请求地址
predicates: #断言 就是配置网关的规则
- Path=/doLogin
discovery:
locator:
lower-case-service-id: true #服务使用小写
enabled: true
eureka:
client:
service-url:
defaultZone: http://121.37.237.168:8761/eureka
registry-fetch-interval-seconds: 3 #间隔多久去拉取服务注册信息
instance:
hostname: localhost
instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port}
创建一个Filter来拦截请求,如果有多个拦截器的话需要同时实现Ordered的getOrder()方法,这个就是标识拦截器的优先级的数字越小,优先级越大。我们这里做的就是IP拦截,如果IP在黑名单之内的话就直接拦截,否则就直接放行。
Gateway 的Filter从作用范围可分为两种: GatewayFilter与GlobalFilter:
GatewayFilter:应用到单个路由或者一个分组的路由上。GlobalFilter:应用到所有的路由上。
然后使用字节流将返回值写入,在 WebFlux 中,Mono 是非阻塞的写法,只有这样,才能发挥 WebFlux 非阻塞 + 异步的特性。
@Component
public class IPCheckFilter implements GlobalFilter, Ordered {
private static final List<String> Black_List= Arrays.asList("127.0.0.1");
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
String ip = request.getHeaders().getHost().getHostString();
if (!Black_List.contains(ip)) {
return chain.filter(exchange);
}
ServerHttpResponse response = exchange.getResponse();
response.getHeaders().set("content-type","application/json;charset=utf-8");
HashMap<String,Object> map = new HashMap<String,Object>(4);
map.put("code", 438);
map.put("msg","黑名单");
ObjectMapper objectMapper = new ObjectMapper();
byte[] bytes = new byte[0];
try {
bytes = objectMapper.writeValueAsBytes(map);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
DataBuffer data = response.bufferFactory().wrap(bytes);
return response.writeWith(Mono.just(data));
}
@Override
public int getOrder() {
return 1;
}
}
再写一个请求端,这个服务也是需要注册到Eureka中,指定项目端口8081,写一个调用接口
@RestController
@CrossOrigin //跨域
public class LoginController {
@GetMapping("doLogin")
public String doLogin() {
String token= UUID.randomUUID().toString();
return token;
}
}
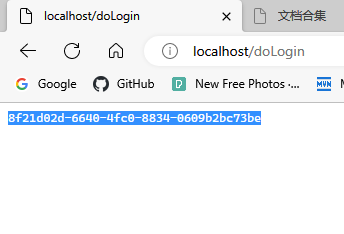
使用localhost发起请求,成功请求
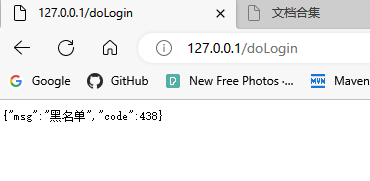
再使用127.0.0.1来请求,拦截成功,因为我们黑名单的判断规则很简单,其实localhost和127.0.0.1其实都是本机
开启负载均衡
lb://服务名就可以开启负载均衡,同时也要将服务发现开启
cloud:
gateway:
enabled: true #开启网关
routes:
- id: login-service-route #唯一标识。默认是一个UUID
#uri: http://localhost:8081
uri: lb://login-service #lb:loadbalance 开启负载均衡
discovery:
locator:
lower-case-service-id: true #服务使用小写
enabled: true #
自定义过滤器
gateway内置了很多过滤器,但是这些一般都不能满足我们业务的需求,所以我们就需要自己自定义过滤器。我们过滤器的返回值就是一个KeyResolver类型。
@Configuration
public class RequestLimitConfig {
@Bean(name = "ipKeyResolver")
@Primary
public KeyResolver ipKeyResolver(){
return exchange -> Mono.just(exchange.getRequest().getHeaders().getHost().getHostString());
}
@Bean(name = "apiKeyResolver")
public KeyResolver apiKeyResolver(){
return exchange -> Mono.just(exchange.getRequest().getPath().value());
}
}
然后我们需要在yml文件中把我们设置的过滤器配置上就行了,这里我们也配置限流策略
routes:
- id: login-service-route #唯一标识。默认是一个UUID
uri: http://localhost:8081
#uri: lb://login-service #lb:loadbalance 开启负载均衡
predicates:
- Path=/doLogin
filters:
- name: RequestRateLimiter #过滤器的名称
args: #过滤器参数
key-resolver: "#{@apiKeyResolver}" #限流策略,对应策略的Bean
redis-rate-limiter.replenishRate: 1 #每秒允许处理的请求数量
redis-rate-limiter.burstCapacity: 2 #每秒最大处理的请求数量
如果我们请求http://localhost/doLogin的次数太快就会提示请求次数限制 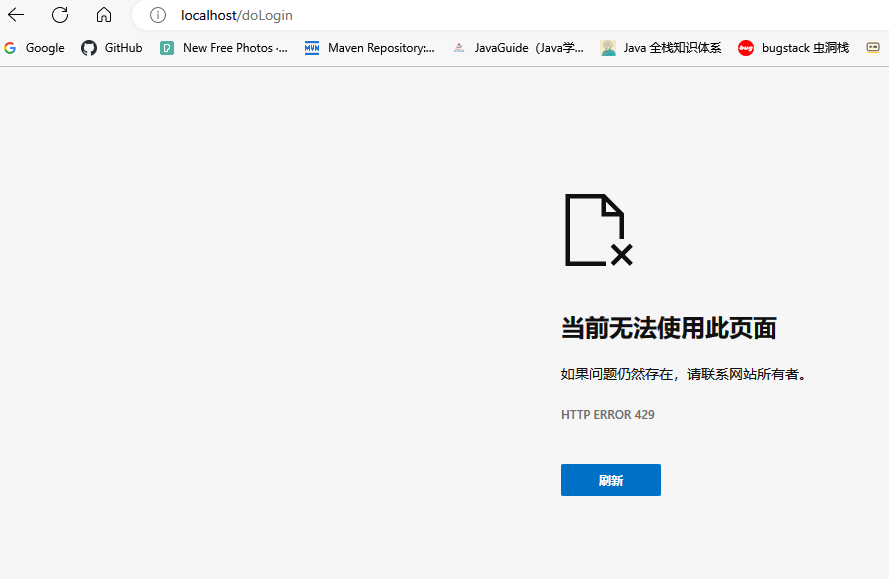
Predicate 断言
断言就是一些匹配规则,满足规则才会进行路由转发,有点路由的前置过滤器的感觉,官方提供了12种断言:
- After:匹配在指定日期时间之后发生的请求。
- Before:匹配在指定日期之前发生的请求。
- Between:需要指定两个日期参数,设定一个时间区间,匹配此时间区间内的请求。
- Cookie:需要指定两个参数,分别为name和regexp(正则表达式),也可以理解Key和Value,匹配具有给定名称且其值与正则表达式匹配的Cookie。
- Header:需要两个参数header和regexp(正则表达式),也可以理解为Key和Value,匹配请求携带信息。
- Host:匹配当前请求是否来自于设置的主机。
- Method:可以设置一个或多个参数,匹配HTTP请求,比如GET、POST
- Path:匹配指定路径下的请求,可以是多个用逗号分隔
- Query:需要指定一个或者多个参数,一个必须参数和一个可选的正则表达式,匹配请求中是否包含第一个参数,如果有两个参数,则匹配请求中第一个参数的值是否符合正则表达式。
- RemoteAddr:匹配指定IP或IP段,符合条件转发。
- Weight:需要两个参数group和weight(int),实现了路由权重功能,按照路由权重选择同一个分组中的路由
- XForwarded:此路由Predicate 允许基于X-Forwarded-For HTTP头过滤请求